

Blockchain Data Indexing: Navigating its working and challenges
Blockchain has been evolving constantly, transforming into a matured technology, empowering diverse enterprises with next-generation dApps and decentralized solutions. Web3 developers and companies working with blockchain rely on different types of blockchain data for various purposes, such as building dApps, integrating crucial data for smart contracts, and providing relevant data into decentralized databases.
Querying these data from the blockchain is challenging as enormous data are stored within blocks, which remain scattered across a decentralized distributed ledger. With blockchain data indexing, seamless access to data is granted while the reach and usability are enhanced significantly. Hence, let’s dive deeper into the concept of blockchain data indexing to explore its working mechanism, challenges, and efficient solutions to overcome the issues.

What is blockchain data indexing and querying?
Blockchain indexing is a method of organizing on-chain data in a way that users can query the information very quickly and without hassle. To fully understand the concept of blockchain data indexing, you should have complete familiarity with how blockchain technology works, the underlying infrastructure, blockchain’s way of enabling data privacy, and use cases of smart contracts powering dApps.
Looking at a real-world example, imagine a book with hundreds of chapters. Whenever readers want to find a specific chapter, they must go through all the pages individually. This approach is quite time-consuming and complex. As a solution, the publisher provides an index at the front of the book followed by the page number so that readers can easily search for the chapter they are looking for.
Regarding blockchain, it’s an immutable, shared, and distributed ledger that records encrypted data across an open, temper-proof, and decentralized network. As evident from the name, blockchain has a series of blocks chained together, creating a time-ordered structure in which transactions are securely stored into blocks, and each block is linked to the preceding blocks, creating a chain-link structure.
While data privacy and security is concealed on the distributed ledger, blockchain lacks a default mechanism to enable high-level query and identification of data. Even when using APIs, you need to be very specific with the queries to be able to fetch the correct data information they need. Blockchain data indexing simplifies how users can search, filter, and locate data for very specific queries as easily as searching information on popular search engines— Google.
To achieve this, blockchain adopts account transaction trace chain (ATTC) and subchain-based account transaction chain (SCATC) index structure of blockchain data indexing, improving the overall efficiency of data querying while systematically indexing all the data such as account details, blocks, and transactions.
How blockchain data indexing works?
As discussed, blockchain data indexing is an approach that automatically reads, filters, and indexes all the data available on blockchain networks, including Ethereum, Polygon, Polkadot, Avalanche, or custom blockchains (AppChains) such as BNB Sidechains, Parachains, Supernets, and Subnets. Hence, data indexing provides an easy-to-query structure for bulk non-compiled data. The following step-by-step process represents the working mechanism of blockchain data indexing:
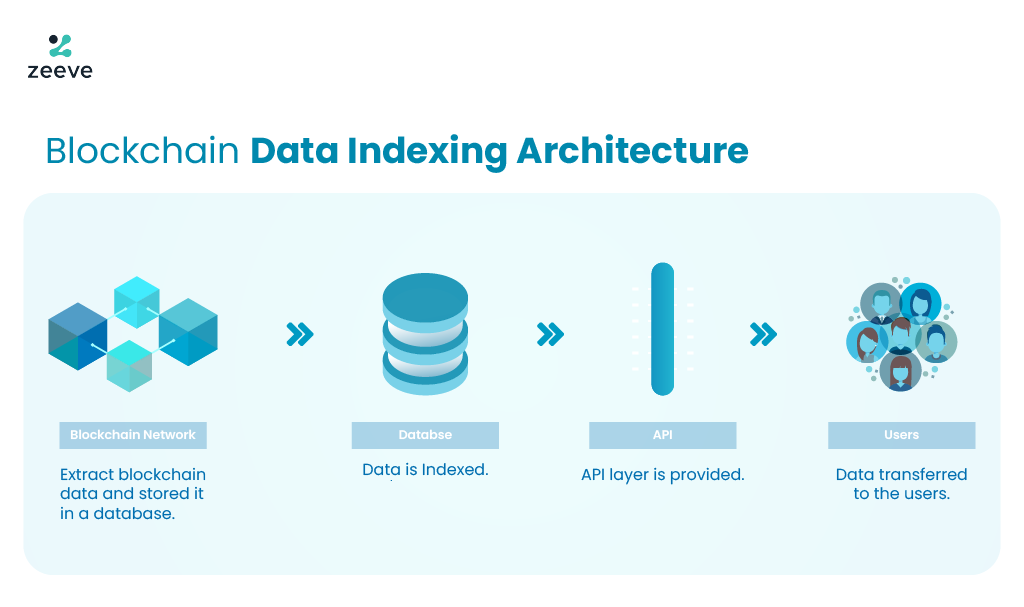
- Data extracted from the blockchain and stored in a distributed database: This process involves parsing the blockchain’s data structures, such as blocks and transactions, to extract relevant information. This information could include transaction details, contract interactions, token transfers, and more.
- Data is indexed in the database: Next, data structures are created to facilitate quick and efficient access to specific types of data. This process employs various indexing techniques based on the type of blockchain and the data being indexed.
Some common indexing methods include:
- Indexing transactions-related information such as sender, recipient, timestamp, and transaction hash.
- Indexing addresses (accounts) to track their balances, transaction history, and other related data.
- Indexing various crypto tokens and NFTs to track token activities and balances.
- Indexing smart contract interactions, events, and parameters.
- Indexing blocks by block height, timestamp, and other relevant parameters.
3. APIs integration: The indexed data is then provided with powerful APIs and user interfaces that allow users and applications to access the indexed data easily. These APIs mainly include GraphQL endpoints and RESTful APIs.
4. Data served to the users: Finally, users and dApps developers can query the indexed data using predefined queries or search criteria. The indexed data allows for much faster and more efficient querying than scanning the entire blockchain.
The challenges with blockchain data indexing and querying
While blockchain powers decentralization, security and transparency into the web3 ecosystem, it lacks native capabilities to support direct and instant retrieval of specific data from the blockchain’s huge and complicated data sets. Hence, Web3 developers or enterprises looking to query the indexed blockchain data have to use external data sources to query the data, which may lead to the following challenges related to blockchain data indexing, and, ultimately, for the querying:
High data volume
Blockchain comprises a digital ledger that stores transactions, which is opposed to the working of traditional data storage systems containing data packets. Blockchain receives data from endless sources, including blockchain ecosystems, centralized, decentralized exchanges, and dApps.
The volume of data increases with more blockchains getting added to the chain over time. Looking at April 2022’s data, blockchain recorded a whopping 389 gigabytes and an increment of 60GB data since the previous year. Data indexing in blockchain becomes challenging to filter data from such a high storage volume. Likewise, querying data from blockchain becomes problematic as well.
Decentralization of data
Decentralized blockchain infrastructure is beneficial in terms of enabling high security, transparency, and data protection against tempering. However, decentralization may create challenges for blockchain data indexing as it distributes data across diverse nodes rather than gathering it at one single point, making it difficult for indexers to access and filter the data.
Lack of efficient query language
Each type of database must have a supported query language to provide correct information based on the user query. Taking the example of a centralized database, they have an initial query language such as SQL. The blockchain’s immutable and decentralized nature does not support the current query languages. Thereby making it difficult for indexers and data consumers to get relevant information.
In the case of dApps, accessing or reading data from the blockchain becomes even more difficult since dApps utilize a different set of data in large amounts. Hence, developers are forced to implement heavy codes to interact with and access desired data.
Data complexity and entanglement
The issues we mentioned in the previous points, including decentralization and lack of query languages, lead to another major issue related to blockchain data access. For example, most second-generation smart contract blockchains record and distribute historical data across separate nodes (externally from the blockchain and its decentralized storage). Therefore, indexing and retrieving these data is usually very complicated because some public nodes need access to such events, resulting in slow data queries.
API Limitations
Current APIs (application programming interfaces) are limited in ensuring public safety against performance-related issues and denial-of-service attacks. Hence, APIs can currently support only simple queries like top-k queries. That’s where Standard APIs turn advantageous, which are fast and efficient APIs to query all types of data ranging from NFTs, Tokens, and multi-chains. For example, developers can retrieve data from NFT marketplaces, virtual worlds, galleries, on-chain data, and multiple cryptocurrency exchanges.
Solution to blockchain indexing issues- Data Indexing Protocols
Data indexing protocols in blockchain can be considered Google for the internet. These protocols are globally-distributed, decentralized infrastructures aiming to solve the challenges of blockchain data indexing while allowing web3 developers to access an open, transparent ecosystem of blockchain data. The Graph Network and Subquery Network are two popular decentralized blockchain indexing protocols for enabling seamless blockchain data indexing in line with offering highly performant and instant data querying.
With The Graph network, enterprises can leverage a unique blockchain tool — indexed “Subgraphs”. A Subgraph, at its core, is an open API that allows dApp developers to retrieve data from advanced blockchains like Ethereum and Avalanche using a unique API query language, GraphQL. Similarly, SubQuery Network offers reliable, flexible, and fully decentralized APIs that allow application developers and data consumers to extract data from blockchain networks. Therefore, SubQuery simplifies the creation of data-rich, future-proof decentralized solutions. With SubQuery SDK, enterprises can build reliable data APIs and start retrieving data indexed from hundreds of networks.
Any developer with expertise in the web3 domain can build Subquery API and Subgraph. For Subgraph, you need to write a custom Subgraph Manifest. This description defines events in the smart contracts regarding the Subgraph, such as the type of event that the contract should focus on, the approach of mapping event data to data, and so on. Talking about SubQuery Network, its open-source SDK enables the effortless creation of APIs that fulfill the unique data requirements of dApps. Let’s have a look at the top benefits of Blockchain indexing protocols for users:
Faster dApp development: Create groundbreaking applications without needing to run your own data server, build indexing infrastructure, or parse through raw data.
Cost reduction: Cut down on costs and time spent running expensive infrastructure by tapping into the competitive data market.
Maximum resilience: Ensure your application’s uptime and keep its data flowing 24/7 with a globally distributed network of contributors.
Conclusion
As evident, blockchain technology is being adopted rapidly, and tons of data is getting produced regularly. This signifies that data indexing protocols will remain important for businesses to perform blockchain data indexing in an efficient and less-complicated way. As such, Web3 enterprises and developers can leverage the technology underlying The Graph and the SubQuery networks. They can create a Shared Subgraph, dedicated indexer, and custom SubQuery API to leverage specific data. This way, data indexing protocols transform the way businesses utilize blockchain data through data indexing and information querying.




Responses